Transforming Business
A Guide to Automation using AI, Machine Learning and Data Science
1. Where do I start?
AI is in the news on a daily basis, with claims of ground-breaking social and financial impacts, revolutionary performance or transformative results. Equally, there are many articles from naysayers, counteracting with warnings and limitations of the technology.
What never gets mentioned from either side of the debate is the high failure rate of AI projects. Gartner expects 30% of AI projects to be abandoned after the proof of concept phase, due to poor data quality, inadequate risk controls, escalating costs or unclear business value. Yet this is not unusual in the software world.
The Standish Group says that 31% of full-scale IT projects are cancelled before completion and only 9% are on time and budget. The recurring reasons for this are a lack of input from end users, incomplete and changing requirements, lack of executive support and technical incompetence. Success requires a plan to deliver clear aims, support throughout the organisation and the skills to execute the technical details.

AI is a relatively new discipline and the governance knowledge and technical skills required are still thin on the ground. Whatever your organisation’s starting point or strategy, there are many considerations to be aware of and pitfalls to avoid to increase the chances of success. This seven-part guide will take you through every step from initial project planning through to ongoing governance requirements once projects are deployed.
What can AI do?
AI and the related disciplines of machine and deep learning are powerful tools. They are not, however, suitable for every challenge and cannot do everything. For example, not every problem is complex enough to require an AI solution – many may be solved with simpler data analysis tools or if-then rule based applications. Similarly, many of the latest AI applications are based on pre-existing frameworks and models, while unique application development requires expensive and experimental cutting-edge research. It may just be that AI isn’t capable of solving your particular challenge in a cost effective way – yet.
How Do I apply AI in my organisation?
An AI project must start with a problem statement. This is a concise description of the issue that the project aims to address. It should identify the problem, explain its impact and set the stage for proposing solutions. A well-crafted problem statement is specific, measurable, achievable, relevant and time-bound (SMART). In the context of AI, however, there are a few things to avoid:
-
Don’t frame the problem in the context of a specific solution e.g. ‘Design a better recommendation engine'
-
Avoid framing the problem in terms of a specific technology e.g. ‘Use an LLM to create product descriptions’
-
Don’t frame the problem by a set of desired features e.g. ‘Our assistant needs to recognise 20 accents’
-
Avoid classifying your problem in the context of what already exists e.g. ‘It should the Siri of financial advice’
-
Don’t presume the behaviour of users e.g. ‘Why would you do it manually if we could automate it?’
-
Try not to solve problems that don’t yet exist e.g. ‘If we do it like that, we’re going to have to do A, B, C also’
Your problem statement should also address:
- Who – who are the stakeholders that are affected by the problem?
- What – what is the current state and the desired state or unmet need?
- When – when is the issue occurring or what is the timeframe involved?
- Where – where is the problem occurring? and
- Why – why is this important or worth solving?
A clearly defined problem statement, will help advance your progress through the remaining stages of your AI projects.

What are the risks?
Leadership teams are likely to be the ones putting together a problem statement. However, few business leaders have a background in data science, so any project objectives need to be clearly understood and translated into distinct goals that can be achieved by an AI model. Be aware that this process may involve compromises to goals and timeframes, and technical teams must be able to communicate any changes to the project scope. Similarly, leadership teams need to be available to discuss options and amend their expectations in accordance with a revised scope.
It is paramount that the problem statement emerging from this scoping phase between leadership and technical teams is clear. Business leaders may state they need an AI model to automatically set prices across a range of products, when what they actually want is a model that sets prices to maximise profit. As the technical team lacks this context, data scientists could work for months to deliver a trained AI model that makes little impact on the business. Alternatively, the technical team may be aware that the present state of data is unsuitable for an AI project. For instance, leaders might assume that detailed daily ecommerce activity reports equate to large amounts of data to train an AI model, while all the data reveals is where a customer clicked. Without data for the complete customer journey, there is no context of why the customer made a decision, which impacts the usefulness of any resulting model.
How do I get buy-in for an AI project?
Even with a well-defined problem statement and great communication between leadership and technical teams, it can be difficult to assess project costs and analyse return on investment (ROI). Your statement should have addressed why the problem is worth solving. The answer includes the value gained, the experience delivered, and the profit realised by implementing the project. Unlike the return on traditional investments, where gains are compared against costs for immediate financial returns, the return on AI investments may be longer term. The benefits of self-service, automation of tasks and using predictive analytics are far-reaching on employee productivity and robust decision making. They create differentiating use cases and transformational initiatives that accumulate over time and contribute to long-term business success.
AI promises unprecedented productivity improvements and business transformation opportunities, but calculating the value of new investments in AI requires you to build a business case by simulating potential cost and value realisation across a range of AI activities.
Gartner, 2023
Although estimated expenses and timeframes shift and evolve as the project progresses and scales, you still have visibility and control. This guide address how to prevent costs spiralling and timeframes slipping at the later stages of an AI project. A well-defined problem statement and project understanding will heighten the chances of stakeholder buy-in and success. While the benefits of AI are realised over longer periods of time, it is also true that small, focused projects offer less room for ambiguity, less data to prepare and work with, and fewer chances to stray from the original problem statement. It may be that the overall scope is broken down into a number of mini-projects that require completing in order to deliver your goal.
Next up: The stages of an AI project and how to prepare your organisation for them.
2. Setting Expectations
An AI project is a complex undertaking, involving a lot of preparation and planning, often accompanied by a steep learning curve and significant investments in compute infrastructure, new skillsets and time.
In the first part of this guide we looked at how to get started, the need for a clearly defined problem statement and project scope, and how to begin setting timeframe estimations and high-level ROI expectations. Here we consider the various stages of an AI project so your organisation is fully prepared for the journey.
Understanding the journey
The journey through an AI project from conception to deployment involves several stages and each one is addressed in detail in the remaining parts of this guide. For now, we summarise these stages to put them in context of each other and assess the relative importance of each one to the whole process. The flow chart below lays out the stages and the order they need to be approached:
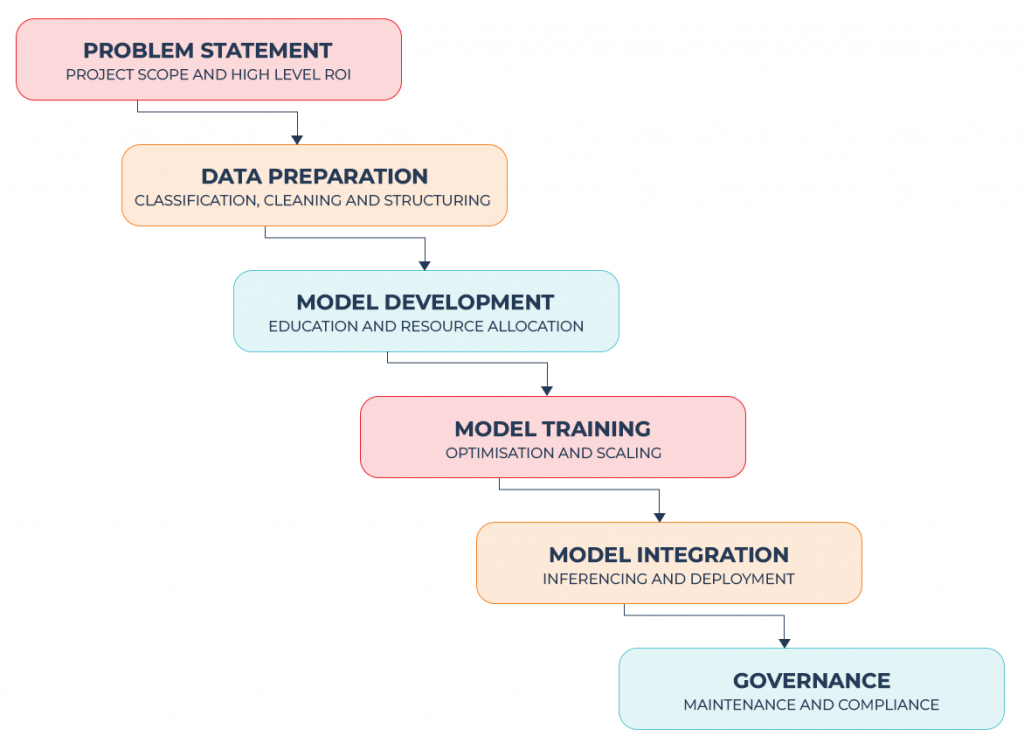
Although the stages must be tackled in this order, as each one is impacted by the one that precedes it, they do not require an equal amount of time or involve even expenditure. The table below shows how both time and costs are likely to be distributed across a typical AI project:
| Stage | % Time | % Cost |
|---|---|---|
| Problem Statement | 5 | 5 |
| Data Preparation | 60 | 10 |
| Model Development | 10 | 10 |
| Model Training | 10 | 60 |
| Model Integration | 10 | 10 |
| Governance | 5 | 5 |
You will see that by far the greatest time and cost commitments are the Data Preparation and Model Training stages. The work required to ensure data is ready for the development of your model is time consuming, while the specialist infrastructure required to train an AI model is the costliest element of the project. These will be explained further in parts three and five of this guide. Nevertheless, the remaining stages with less time or cost commitment are also important.
Setting realistic expectations
Although producing the problem statement is the initial stage, the accuracy of its details will be informed by understanding the relevant costs and timeframes expected at later stages of the project. Expect AI projects to be long – organisations should allow at least a year to see some results, assuming parameters, goals and objectives are not changed within this period. Also avoid the temptation to rush any stages – skimping on your data preparation or under-optimising your model prior to training, will result in higher costs down the line and impact the project’s expected outcomes. Similarly, under-investment in hardware at the training stage may reduce costs in the short term, but timeframes will lengthen, adding other expenses and potentially compromising entire project goals.
Notwithstanding Gartner’s report saying that over 30% of AI projects are expected to fail, interview-based research from Germany in 2022 revealed that four out of five AI projects had failed. The main causes were the lack of a clear plan, poor data, underinvestment in infrastructure, unrealistic expectations, and jumping on the bandwagon, rather than assessing whether AI was the correct tool for a particular problem. These are initial project problems and there will be more that arise after significant time and money has been invested, if training and integration are not executed well enough.
Next up: Data preparation and ensuring you have the best chance of success by starting with clean, categorised, labelled and structured data.
3. Data Preparation
The previous part of this guide dealt with setting expectations within your organisation. We covered the main stages of an AI project and how you should expect to allocate time and costs between them. This part will focus on the first ‘hands-on’ stage – data preparation.
Data is key to any AI project and the scope of the project has a direct impact on the data required. The larger it is, the more data is needed and the more preparation required, as it is the quality of the data that is the most critical determinant of project success.
Why good data is important
AI is a field of computer science that aims to create intelligent agents capable of reasoning, learning and autonomous action. The quality of data used to train and test AI models determines how reliable, accurate and ethical those agents are, and lays the foundation for effective learning, bias mitigation, efficiency, generalisability and improved performance. The volume of data required is task dependent and, for example, a predictive maintenance model requires much less data than an LLM designed to generate new content.
The more data you are working with, the longer the timeframe required to structure, clean and engineer it to develop a model that could be internally or commercially deployed. Even though every generation of GPU delivers the promise of significant performance increases over the last, shortening times to results with growing numbers of parallel processing cores and more advanced memory configurations, it all counts for nothing if data is of a poor quality.

Around 60% of time spent developing AI models is at the data preparation stage
Poor data quality can cover a number of issues:
- incompleteness jeopardises prediction models, for example running credit checks with income data missing,
- inconsistencies such as age not matching birthdate necessitate data cleaning before performing analysis,
- outliers can skew results and distort patterns and often result from inputting errors,
- duplicates can lead to overrepresentation of points introducing bias, and
- volume, as you may not have enough data to train the model effectively.
When starting any AI project the technical team need to keep leaders informed about the state of data and realistic timeframes needed prepare it for effective use. Similarly, leaders need to understand that time taken here will benefit the outcomes and that it is estimated that around 60% of time spent developing AI models is at the data preparation stage. Additionally, input from subject matter experts is important for data preparation, as technology teams may not understand the impact and weight of any given attribute, or its importance in the final model.
What does data preparation involve?
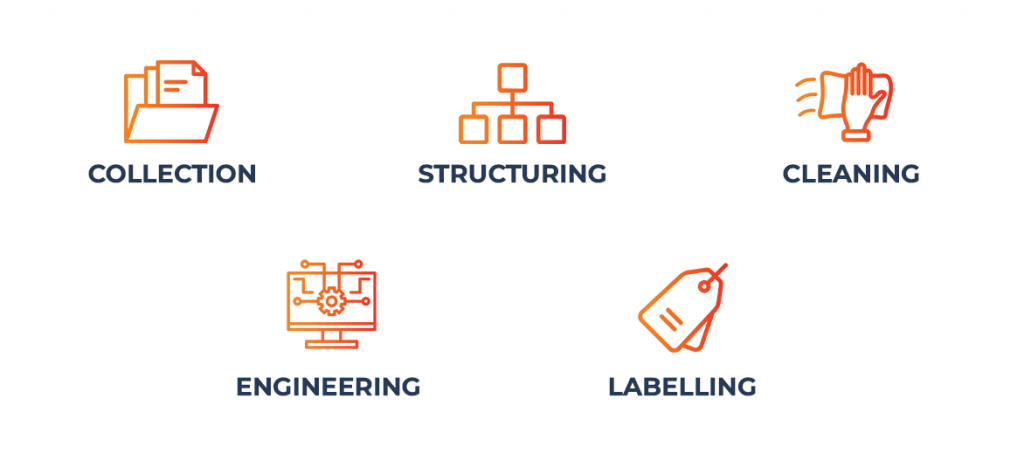
Data preparation is often seen as a boring task, but don’t fall into the trap of seeing this as ‘menial work’ not worthy of investing time and resource into, as this stage forms the bedrock of future success. Data preparation is a multi-step process that involves data collection, structuring, cleaning, feature engineering, and finally labelling.
Once you have collected data from relevant and varied sources, you begin preparation by structuring it. This involves defining the relationships between different data elements to enable efficient storage and retrieval of data. For instance, by using a customer ID to link account and order information. Next, data cleaning identifies and corrects errors, inaccuracies and inconsistencies, by infilling missing data, addressing inconsistent formatting, using statistical techniques to adjust outliers and removing duplicates.
MSBC prepared data from paid providers for a FinTech supplying minute-by-minute stock market trading analytics for professional investors. Each data provider had a unique security classification system, while the FinTech used its own version. Some providers did not distinguish between different classes of shares and in the absence of a European Consolidated Tape, there were disagreements over how many shares traded each day.
MSBC addressed this issue by creating a unified security symbology, disaggregating volume into classes of shares, and providing options for users of the data to apply their preferred definition of trading volume. The result was a consistent and flexible application that met our client’s customers’ expectations.
The absence of a European Consolidated Tape led to disagreements over how many shares traded each day. MSBC developed a consistent and flexible application that met client expectations.
While structuring and cleaning are ways of refining data, the next process of feature engineering creates attributes to enhance it. Feature engineering allows you to define the most important information in your dataset and use domain expertise to get the most out of it. This might involve scaling, one-hot encoding, binning and time series features to capture temporal patterns. Finally, data labelling is required to signpost differing types of data in your dataset. For example, specifying which parts of the data the AI model will learn from, as when labelling noise in podcasts to ignore it. Though improvements in unsupervised learning have resulted in AI projects that do not require labelled data, many systems still rely on it to learn and perform their given tasks.
| Feature | Definition |
|---|---|
| Scaling (a.k.a. normalisation or standardisation) | Transforming numerical values to a common scale, for example 0 to 1, or a standard normal distribution with a mean of 0 and a standard deviation of 1. |
| One-Hot Encoding | Transforming categorical data into binary form and treating each as independent. For example, representing male and female as 0 and 1 without ordinality. |
| Binning (a.k.a. bucketing) | Grouping numerical values into discreet intervals to reduce noise and the impact of outliers. Intervals may be equal width, equal frequency, quantile or custom. |
| Time Series Features | Capturing patterns and trends in time-stamped data. |
Preparing data and investing in toolkits and applications at this stage will ensure you don’t end up in a development loop, where no outcomes are good enough to proceed to training, effectively ending the project. Mistakes at this stage can poison future results and may compromise the project.
How long does it take?
As we indicated in part two of this guide, data preparation is a significant stage of an entire AI project, but the time it takes will depend on the resources you apply to it. A common mistake is to assume that data preparation is not worthy of your best data scientists’ time, as they should be concentrating on the ‘real AI work’. However, your most skilled people will be invaluable at sanity checking work already carried out and in deploying AI to curate data for other AI, including the production of synthetic data. The involvement of top engineers will have a positive impact down the line and save time and costs later.
There are numerous tools and services that can aid with data structuring, cleaning and labelling, while feature engineering applications help ensure you are using the right data in the first place, spotting trends and patterns that may not be immediately obvious.
However, choosing the best tools to suit your data may not be obvious, so partnering with an expert AI organisation offering data science consultancy may be a key investment at this stage. MSBC has a comprehensive suite of professional services designed for every stage of an AI project.
Next up: The model development stage, ensuring you have the correct skills, appropriate IT infrastructure and technical support.
4. Model Development
The previous part of this guide focused on data preparation – an important stage, as the quality of your data impacts the effectiveness and integrity of the next stage – model development.
Model development is where you first apply your prepared datasets, in small batches, to test, tweak and test again, to identify a successful outcome that you want to scale and train into a fully-fledged AI model.
Don’t start from scratch
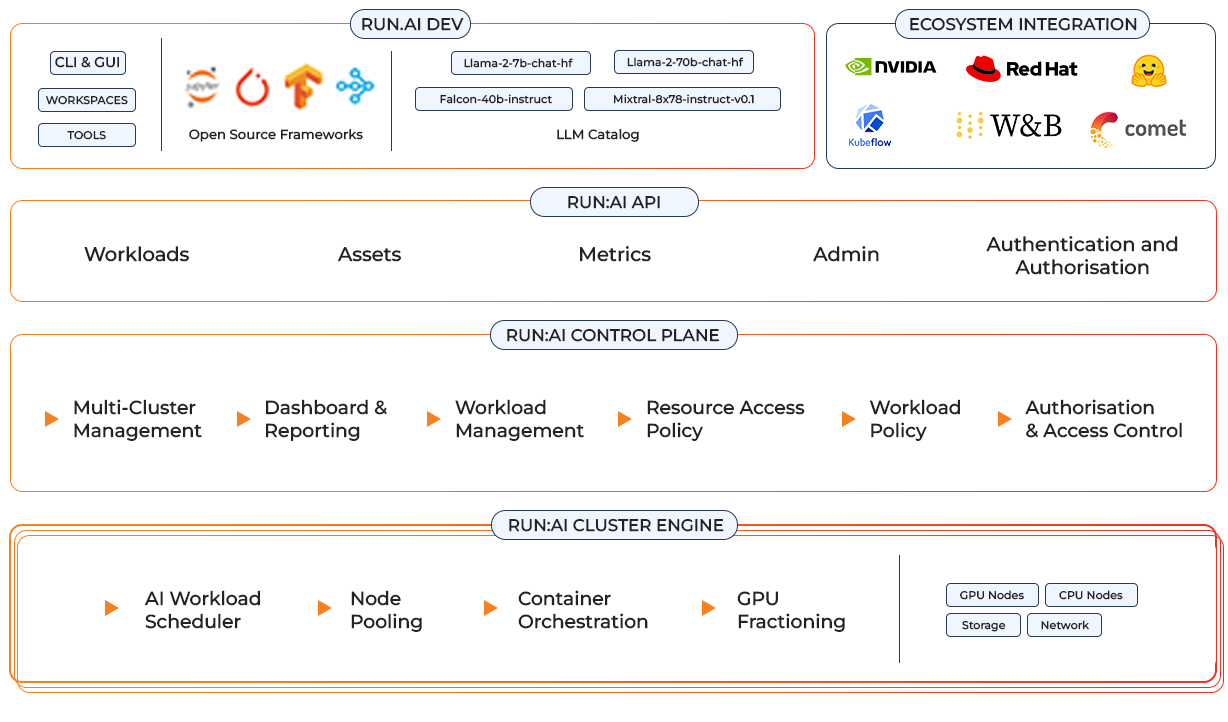
The chances are that your AI project is not unique – even if the outcome is specific to your organisation, it is likely someone in a related industry has applied the same logic. Using optimised foundation models (FMs) saves time and effort when building an AI pipeline, and an increasing variety of software solutions are removing the need for much of the subsequent development work. A prime example is the NVIDIA AI Enterprise (NVAIE) platform, which features in excess of 30 distinct and interlinked pre-trained frameworks. These are optimised for NVIDIA GPUs and designed for end-to-end implementation of AI projects such as medical imaging, autonomous vehicles, avatars, drug discovery, robotics, generative AI and many more.

Starting with FMs may help advance your project development. These are large scale, general purpose models with text, audio or video inputs that may be connected to project-specific data for further training, using Retrieval Augmented Generation (RAG) and fine-tuning. The NVIDIA AI Enterprise platform hosts a combination of open and closed-source models and enterprise-ready software to accelerate specialist model training. For most companies the cost of developing an FM from scratch is prohibitive and unnecessary, given the wide choice of pre-trained models available and a preference for working on developing AI for business workflows rather than setting up the system. Our team of MSBC AI experts is ready to support you in selecting models and allowing you to focus on inference and time to first token.
One area that our consultants may discuss with you is the constant evolution of AI and the new frameworks and toolkits that are announced almost weekly. However, focusing too heavily on using new cutting-edge approaches may lead to a mismatch between what could be achieved and what your organisation is actually looking for. It is important to build AI systems that are backwards and forwards compatible.
What hardware do I need?
Buy
As you’ll only be using small batches of data to test models during the development phase, you don’t need a huge amount of GPU power to get started. An AI Development Workstation (or dev box), powered by the latest NVIDIA GPU-accelerators is ideal for the first stage of AI projects, enabling data scientists to develop and debug models. Entry-level workstations are powered by a single NVIDIA GPU, scaling up to six GPUs for maximum performance.

Rent
Alternatively, you can avoid hardware expenditure by doing your model development on a cloud service, designed for AI workloads. They are available in flexible increments of one week, one month, three months, six months and one year. Access is straight forward from any device, using a secure OpenVPN connection.
MSBC can advise you as well as setting up and configuring your service.

Optimising your model
To ensure the optimal performance of training and full-scale production, it is wise to split your data into three sets: training, validation and test. Firstly, training data is used by the model to learn the patterns and features of the data and to make predictions and decisions. Then validation data is used to experiment with different algorithms, architectures and parameters, to find the optimal combination for your goal. Finally, test data is used to evaluate your chosen model’s performance on unseen data and estimate how well it will generalise to new situations.
You should evaluate your model on various metrics and dimensions, for example accuracy metrics such as precision, recall and F1-score, summarised in a confusion matrix. Visualise the trade-off between sensitivity and specificity using ROC (Receiver Operating Characteristic) curves, and numerical measures of ROC such as AUC (Area Under Curve).
You will need in-depth knowledge to optimise your model and training your existing teams will take time. New hires in this sector are sought after and in short supply. It is worth considering orchestration platforms that help visualise and understand the status of your AI workflows and any issues that may be occurring. This will minimise their impact and avoid repeating them. To this end many organisations that cannot make these investments in breadth and depth of talent are partnering with experts in the field. MSBC data science consultancy services will help your teams ensure their chosen model is ready for scaling, minimising delays and false starts when you begin full production training.
Next up: Model training and ensuring you have the correct infrastructure and technical support for your goals.
5. Model Training
The previous section looked at model development – using GPU-accelerated resources to test and optimise models prior to selecting the best one to train and scale.
Model training is where your final development model is put through many iterations to result in your final full production model. It is the most expensive phase of an AI project, so it is vital to have the most suitable hardware and software infrastructure for your goals and expected outcomes.
Invest in infrastructure
Once a development pipeline has been established and an AI model is ready for production, the next step is to train the AI model against your training dataset. The training phase requires significant GPU and storage resources as many iterations will be needed – it is therefore the most expensive part of any AI project. Training requires much more hardware resource – at minimum a multi-GPU server, supported by fast storage and connected by high-throughput, low-latency networking. If these three component parts of your AI infrastructure are not matched or optimised, productivity and efficiency will be impacted. The fastest GPU-accelerated super computer will be a waste of money if connected to slow storage that cannot keep its GPUs 100% utilised.

Accelerated compute
Harness the power of NVIDIA GPUs in custom designed 3XS Systems EGX or HGX servers. Built from the ground up with AI workloads in mind, our MSBC partner’s system build division produces fully-configurable server solutions, tailored to every size of AI project. For larger projects NVIDIA DGX appliances may be a better alternative.

AI-optimised storage
Specialist providers develop software defined storage (SDS) platforms from the ground up for AI workloads to complement the NVIDIA EGX, HGX and DGX range of servers. Delivering ultra-low latency and tremendous bandwidth at a price which allows more investment to be made on GPU resource and less on storage.

AI-ready networking
NVIDIA Spectrum Ethernet and Quantum InfiniBand switches matched to your servers, provide the throughput and latency required for AI workloads. Offering speeds of up to 800Gb/s and outstanding resiliency, they ensure maximum GPU utilisation across your entire infrastructure.
Our team of MSBC AI experts can design, install and manage your AI infrastructure – either on your premises or hosted with a datacentre partner – ensuring optimal performance at all times, delivering maximum ROI for your organisation.
To buy or to rent?
The GPU-accelerated systems needed for the training phase of AI projects represent the largest single cost, so if you intend to purchase an in-house infrastructure you need to consider the GPU optimisation and utilisation points above. You will also need to consider the complexities of connecting and configuring servers and storage using high throughput, low-latency networking solutions, and where to house them – on premise or hosted in a datacentre. Purchasing and owning this complete infrastructure is one approach – using a cloud service provider (CSP) is an alternative.
32% of enterprises use only a public cloud approach, 32% use only a private cloud approach, and 36% use both.
Enterprise Technology Research, 2023
As either option comes with pros and cons, deploying hybrid environments allowing for the best of both worlds, is becoming the norm. As AI projects require different resources at the development, training and inferencing stages, a hybrid deployment allows for the cost control and integrity for sensitive data associated with owning hardware, alongside the ability to burst into public GPU compute farms in the cloud when extra capacity is needed fast.
There are many horror stories of cloud costs spiralling wildly. Retaining some element of on-premise hardware reduces this risk, coupled with the practice of optimising models prior to training, thereby ensuring any CSP GPU instances are correctly sized, monitored and controlled. Look for a CSP with a pedigree in AI and that offers support from engineers and data scientists, rather than a ‘hands-off’ hyperscaler provider. It is essential to be able to scale your project without over reliance on either on-premise or cloud services. This balancing is to ensure that costs do not get out of hand and project overspend leads to the benefits being forgotten.
The Cloud Difference
Cloud platforms should be designed to accelerate GPU-demanding applications, rather than adapted from general purpose systems. Additionally, workload specialists will guide you through every stage, from initial proof of concept right through to deployed solution.
RAG and Fine-Tuning your model
If your model was based on a foundation model (FM) or from previous work you have done, it will require project-specific training to improve its accuracy. Retrieval Augmented Generation (RAG) is a technique for querying additional data and combining it with the original query, to provide greater context for language models. Fine-tuning is a technique to alter some or all of the model weights, using a new dataset to better fit a specific task. A backpropagation algorithm passes examples from the dataset to the model and collects its outputs, calculating the gradient of the loss between the model’s actual and expected outputs. The model’s parameters are then updated to reduce the loss, using a gradient descent or adaptive learning rate algorithm. This is repeated for multiple epochs until the model converges.
Next up: Integration of larger models with other workflows and infrastructures as training progresses.
6. Model Integration
Part five of this seven-part guide focused on the training hardware and skillsets required to scale and fine-tune your model, ready for inferencing with unseen data and full-scale deployment.
However, for more complex algorithms such as large language models (LLMs) and Generative AI deployments, training workflows often require hybrid environments, where dataset movement and model integration into other workflows are key.
Computing at scale
During training, an AI model learns from data to make decisions or predictions, but when it comes to large-scale AI models the training step differs from the normal process. Distributed computing and parallelism are key strategies for decreasing training times and handling the extensive data involved in large-scale AI models. The main distinction between distributed computing and parallelism lies in their scope and implementation.
Parallelism speeds up data processing by simultaneously performing multiple tasks on the dataset – either on a single GPU system or across multiple systems. This includes data parallelism, where multiple sets of data are processed simultaneously; model parallelism, where different parts of the model are processed on different machines; and pipeline parallelism, where different stages of the model are distributed across multiple processors for simultaneous processing.
Distributed computing, on the other hand, refers to the specific use of multiple systems—a network of interconnected computers or a cluster—to handle and analyse large amounts of data, with the results from each system aggregated to form the final output. Often distributed computing and parallelism work in tandem. Distributed computing serves as the outer layer of the training structure, processing vast datasets by expanding the hardware’s capacity. Parallelism serves as its inner layer, enhancing the efficiency within this expanded setup.
Advanced hardware
AI training requires multiple GPUs. However, for LLMs or Gen AI, hundreds of GPUs may be required. Large scale clusters or POD architectures are available for this purpose, comprising the necessary number of GPUs and advanced networking in the form of DPUs (Data Processing Units). DPUs contain dedicated onboard processors for hardware accelerated data transfer, compression, decompression and encryption to ensure data integrity across your cluster.

Cluster management software
The right software allows intelligent resource management and consumption so that users can easily access GPU fractions, multiple GPUs or clusters of servers for workloads of every size and stage of the AI lifecycle. This ensures that all available compute can be utilised and GPUs never have to sit idle. A scheduler is a simple plug-in for platforms such as Kubernetes and adds high-performance orchestration to your containerised AI workloads, developed using distributed training frameworks such as TensorFlow and PyTorch.
Where should I allocate workloads?
In the previous part of this guide, we recommended a hybrid on-premise and cloud strategy as the best approach to scaling AI projects efficiently and cost-effectively. For LLMs and Gen AI projects it is absolutely essential to leverage both private and public clouds, to cope with the distributed training nature and vast amounts of data. A private cloud refers to your own infrastructure, however it may be split over numerous company buildings and hosted in datacentres. Private cloud facilities may suit businesses or organisations with stringent security, privacy or regulatory requirements, as they allow full control over data, infrastructure and AI operations.
In contrast, public clouds are leveraged to scale models with less upfront hardware investment. Organisations with non-sensitive data or few regulatory restrictions, may use public cloud to benefit from near-infinite GPU scaling, retaining only their most precious data on in-house systems. It is also true that public cloud scale advantages may address short-term time pressures at any stage of the project.
Federated Learning
In use cases where data security is paramount, such as healthcare where patient anonymity is essential, a federated learning infrastructure can be deployed. Federated learning is a way to apply distributed training to AI models at scale without anyone seeing or touching your data, by processing data at source in a private cloud environment.
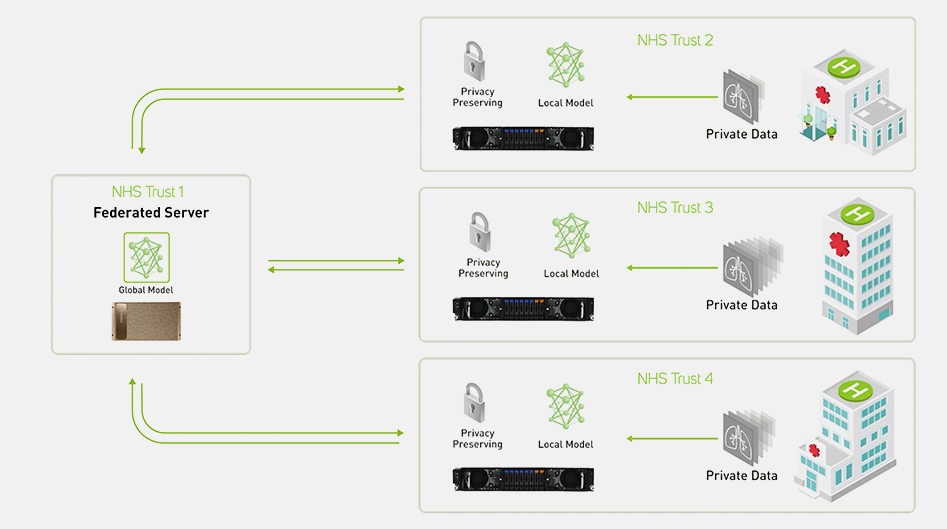
Other things to consider
AI workloads contained within an on-premise server room, isolated from the wider corporate network, may be considered relatively secure. However, when it comes to larger scale models employing distributed training and integration across private and public cloud environments, there are a number of other factors to consider:
Data encryption – data must be encrypted in transit and at rest using robust standards, protecting sensitive information from unauthorised access and tampering.
Access control – strict access control measures, such as role-based access and multi-factor authentication, should be implemented.
Adversarial attacks – defend against attempts to manipulate AI models using techniques such as adversarial training and robust optimisation to improve model resilience.
Disaster response – monitor AI systems for unusual activity or anomalies that might indicate security breaches, in conjunction with a response plan to mitigate any security incidents.
Supply chain security – verify the integrity of third-party tools and libraries by regularly updating and patching to protect against known vulnerabilities.
MSBC’s professional services division is able to help with initial infrastructure health checks, cybersecurity audits and policy planning.
Next up: The final step of this guide focuses on governance and regulatory compliance in your deployed AI project.
7. Governance
The penultimate part of this guide dealt with the hybrid environments required when AI algorithms scale to GPU-clusters, hybrid clouds and beyond, and addressed data integrity and security concerns.
This final part details the compliance and regulatory requirements that are becoming common in the AI industry, helping you to be aware of impacts on your model development and deployment.
The EU AI Act
The AI Act is a regulation establishing a common compliance and legal framework for AI within the European Union (EU). It came into force on 1 August 2024, with provisions becoming operational over the following six to 36 months. It covers all types of AI across a broad range of sectors, with exceptions for military, national security, research and non-professional purposes. The Act classifies non-exempt AI applications by their risk of causing harm into four levels – unacceptable, high, limited, minimal – plus an additional category for general-purpose AI; as follows:
Unacceptable risk – AI applications in this category are banned, except for specific exemptions. When no exemption applies, this includes AI applications that manipulate human behaviour, those that use real-time remote biometric identification, such as facial recognition in public spaces, and those used for social scoring – ranking individuals based on their personal characteristics, socio-economic status or behaviour.
High-risk – AI applications that are expected to pose significant threats to health, safety, or people’s fundamental rights. Notably, AI systems used in health, education, recruitment, critical infrastructure management, law enforcement and justice. They are subject to quality, transparency, human oversight and safety obligations, and in some cases require a Fundamental Rights Impact Assessment before deployment. They must be evaluated both before they are placed on the market and throughout their life cycle.
Limited risk – AI applications in this category have transparency obligations, ensuring users are told that they are interacting with an AI system and allowing them to make informed choices. This category includes AI applications that make it possible to generate or manipulate images, sound, or videos, and would capture deepfakes.
Minimal risk – AI applications that fall in this category require no regulation. It includes AI systems used for video games and spam filters.
General-purpose AI – AI applications in this category include foundation models such as ChatGPT. Unless the weights and model architecture are released under free and open source licence, in which case only a training data summary and a copyright compliance policy are required, they are subject to transparency requirements and potentially an evaluation process.
Early on in your AI project it would be wise to understand which of the categories it falls in, to understand the degree of regulatory burden required and transparency expected.
82% of companies have already adopted or are exploring artificial intelligence (AI) solutions.
IBM AI Global Adoption Report, 2024
ISO 42001
The rapid growth of AI has brought up many ethical, privacy and security concerns. As a result, the International Organisation for Standardisation (ISO) and the International Electrotechnical Commission (IEC) have developed a new standard - ISO/IEC 42001:2023 or simply ISO 42001. This is defined as “an international standard that specifies requirements for establishing, implementing, maintaining, and continually improving an artificial intelligence management system (AIMS) within organisations.” Attaining this accreditation demonstrates an organisation has trustworthy AI practices, as summarised below:
Transparency
Any decisions made using an AI system must be fully transparent and without bias or negative societal or environmental implications.
The MSBC AI Ecosystem
We hope this guide has demonstrated that any AI project keeps evolving and is made up of numerous interlinking stages and processes that each and collectively determine success. To address this complex landscape, MSBC has a partner network of hardware, software and services to help you get the most from every aspect of your AI project.
We support your organisation every step of the way – from mindshare, first principles and proof of concept; to hardware audits, new system design and data science consultancy; through to infrastructure optimisation, cloud deployment, installation, configuration and post-deployment support services. We hope you found this guide useful in providing some guidance and suggested structure to your AI projects.
MSBC is an NVIDIA Solution Advisor: Consultant that provides consultation services and expert advice to customers looking to implement NVIDIA-based solutions or technology.